ZStack Cloud Platform
Single Server, Free Trial for One Year

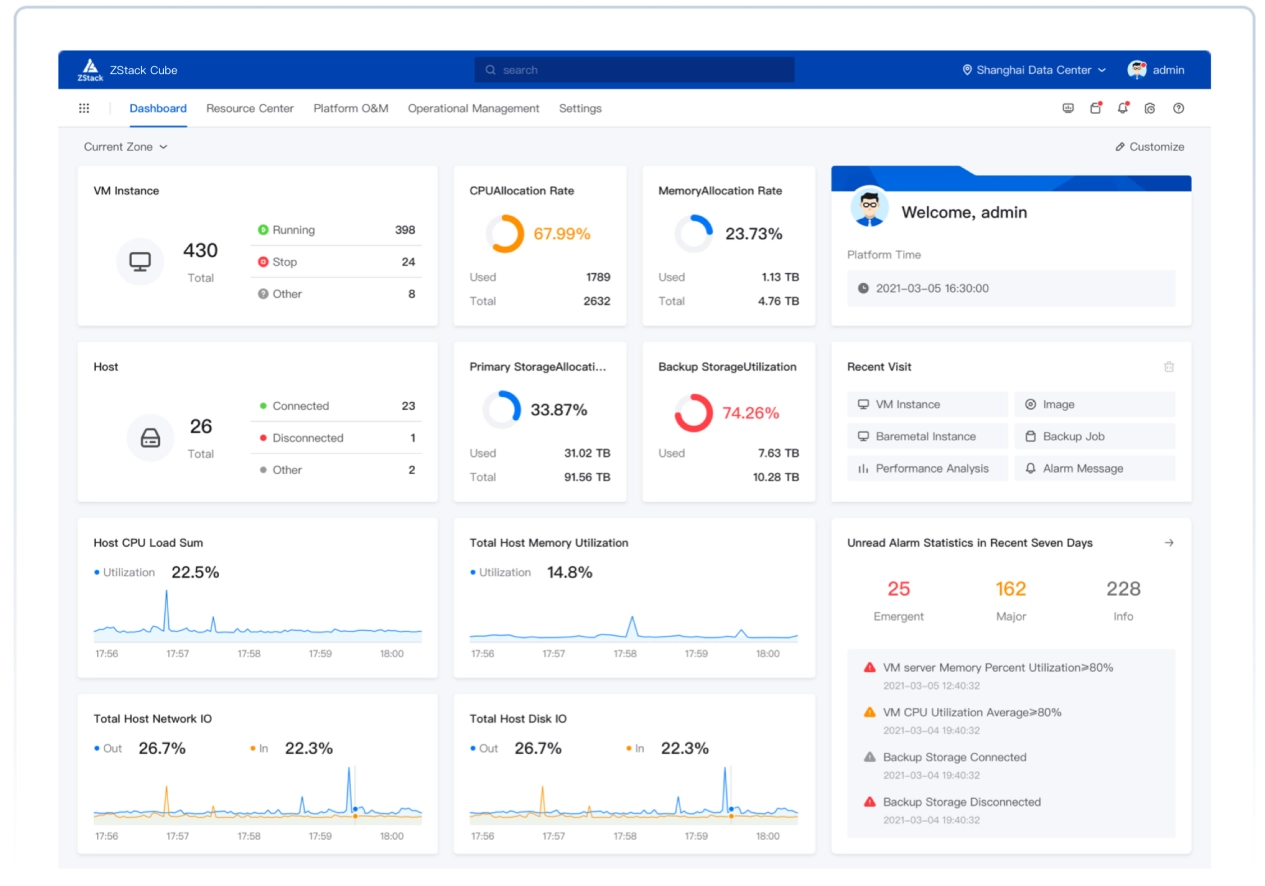
Comprehensive product documentation and tools

Upholding the value of Customer First and the mission of Serving Customer, ZStack is dedicated to providing secure and stable services for customers.

To educate ZStack partners and interested individuals about cloud computing and to cultivate cloud computing talent.

ZStack provides innovative cloud infrastructure for ten major industries

The report provides three major
solutions and customer case studies for transitioning from VMware to ZStack.
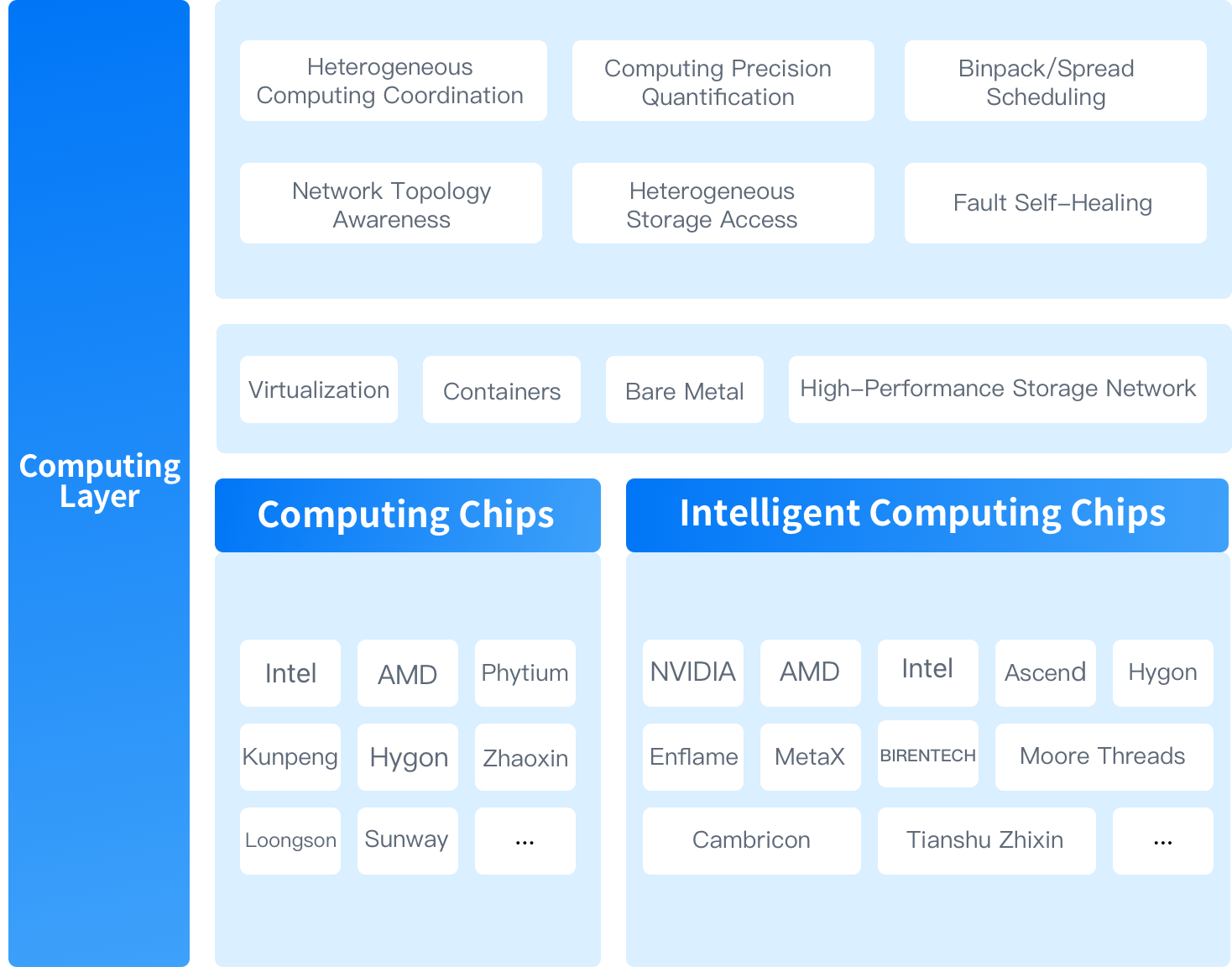
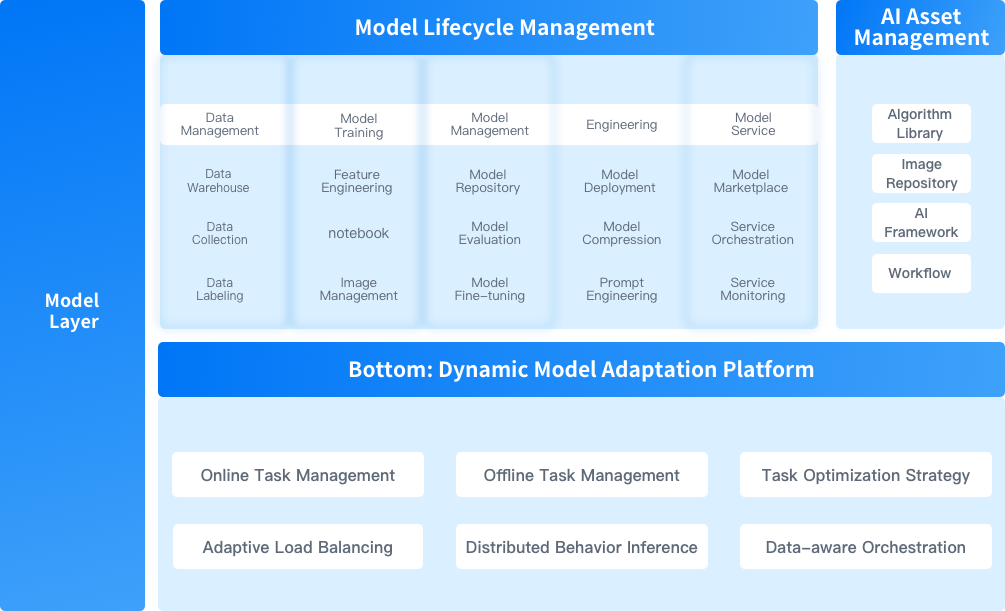
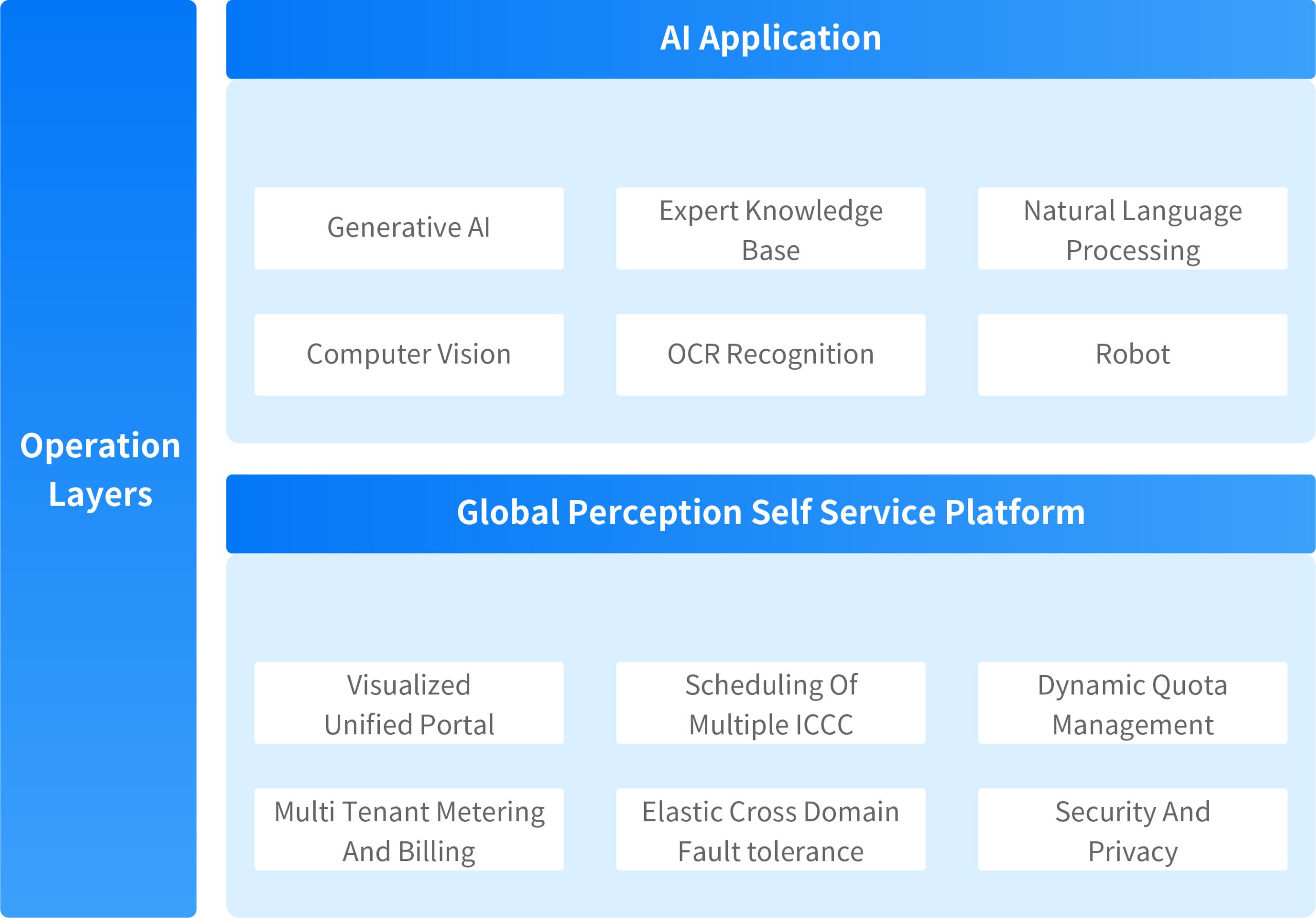
The privatized AI infrastructure platform comprehensively supports enterprise-level AI applications in three key areas: 'compute power scheduling, AI large model training and inference, and AI application service development'
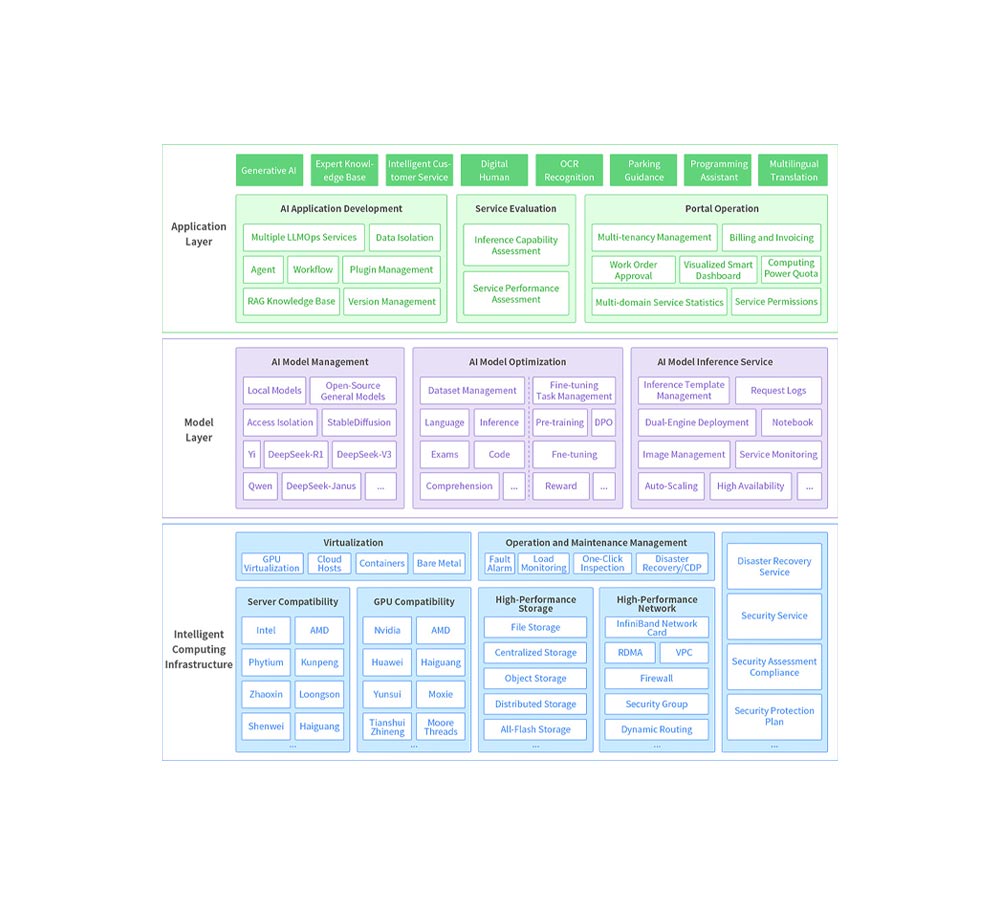
ZStack AIOS is a self-developed, productized, and standardized next-generation AI infrastructure operating system. Centered around “AI,” it facilitates AI innovation through three key layers: the computing power layer, the model layer, and the operational layer. It supports seamless upgrades from cloud platforms and is compatible with all cloud infrastructure module services, product documentation, and after-sales services.